A time series course with Julia
Last semester, I took a time series course where we implemented some models like the Hodrick-Prescott filter or structural vector autoregressive processes in Julia. The whole thing is available online with the notebooks running on Binder which allows you to go through the programming examples in your browser. If you plan to use Julia yourself and want to play around, it might be a place to start.
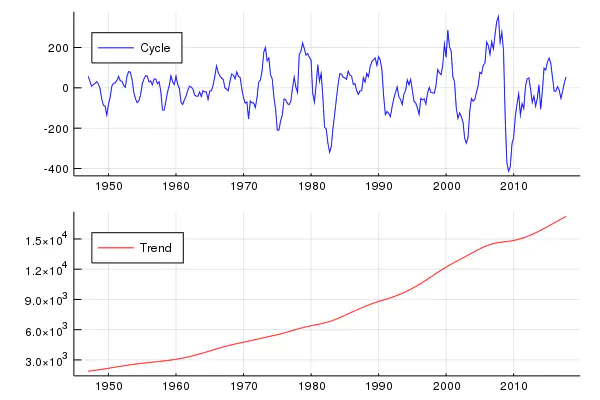 An example for a Hodrick-Prescott filter.
An example for a Hodrick-Prescott filter.
If you are here for some examples of time series analysis in Julia, you are right where you belong. If you are looking for opinions on Julia and how it fits into the scientific computational landscape, you should read these posts:
- Why Numba and Cython are not substitutes for Julia by Christopher Rackauckas
- JAX vs Julia (vs PyTorch) by Patrick Kidger
As I had not used Julia before and only heard about how fast it is, that it is statically typed, and so on, I was very interested in the beginning, but that changed quickly.
The main cause of frustration was that the Julia developers released three versions during the time of the course. Version 0.6.4 was released on 9 July 2018, version 0.7.0 and 1.0.0 followed on 8 and 9 August respectively. All versions changed the main parts of the API and probably the last change made most standard modules importable. As much as I appreciate the effort of making a language more modular and optimizing the structure, the changes probably broke all code examples on the web which totally clashes with my way of learning a new language by copying and pasting parts together. At least, one can assume that the changes will be minor in the future after the release of 1.0.0.
Another disadvantage is that Julia cannot be shipped with conda on Windows which is still my platform of choice, but maybe I am the one to blame here 😄.
Apart from that, I do not know much about Julia and my current critique is more about convenience which comes with a more mature language. Comparing a 27-year-old to a 6-year-old is unfair.
The main selling points of Julia are speed and its mixture of dynamic and static typing. Regarding the first item, Python can be brought to comparable speed by using CPython or Numba, but all the benchmarks always depend on whether you hold the implementation over all languages constant or whether you optimized the problem for each language and whether there is a huge difference between a simple program and large implementation. So, I am not very sure what the final answer is here. Furthermore, all projects are heavily under development and benchmarks are quickly outdated. Regarding static typing, I think it would make some data analyses more consistent and currently, there is no real match in Python.
Maybe I will use Julia in the future, but currently, I am too comfortable with Python and do not have a real use case where I am forced to switch to something else. Path dependency is a bitch.
Tobias Raabe
I am a data scientist and programmer living in Hamburg.